Having used dlib for face landmark detection task, implementing my own neural network to achieve similar goal can be potentially fun and help the learning process. There is this recently released paper that outlines the approach of using machine learning in setting parameters used in traditional statistical models. The author is nice enough to release his source code, which can be a great starting point. So I forked from there, changed code to remove some bulky dependencies, and sort of re-writing it to better fit my mental model and in the process understand it better.
Face landmark detection problem can be broken down into face detection and landmark detection. Face detection deals with identifying position of faces within an image whereas landmark detection marks points of lips, nose, eyes in the detected face. The above mentioned paper leaves face detection to popular libraries like dlib, opencv and concerns itself mainly with landmark detection. So subsequent steps assumes that bounding box of face is known. Complete code can be found here.
Prepare Training data
In order to accomplish what dlib does, the first step is to obtain the dataset on which dlib train. It can be downloaded from here. Download and unpack, we got a dataset which is the combination of AFW, HELEN, iBUG and LFPW face landmark dataset. xml files labels_ibug_300W_train.xml and labels_ibug_300W_test.xml contain target landmark coordinates.
In this step, training images are read, cropped to bounding box of target face, and then converted to grayscale. Working with grayscale reduces the number of input channels, results in less complex network model while still maintains information about landmark positions. And since neural network takes a fixed size input, we need to resize images to a fixed width and height (in this case, 224). Preprocessed images are shuffled and saved as numpy array for latter training.
def preprocess(lmk_xml):
#...
# read, crop and convert to grayscale
data, labels = read_data(lmk_xml)
# shuffle data
data, labels = randomize(data, labels)
# visualize to test correctness after randomizing
view_img(data[1], labels[1])
np.savez(save_f, data=data, labels=labels)
Constructing the model
According to the paper, network model consists of 2 layers. A feature extraction layer that extracts feature vector from input images and feed forward to a PCA and transformation layer. PCA is fundamental in shape modelling. PCA decomposes the sample space into components (eigen vectors) along which variance between samples are maximized. Given principle components, a shape can be modelled by:
\[ shape = mean + \sum_{k=1}^{m} (scores * eigenvectors) \]
PCA calculation can be done simply with scikit-learn.
from sklearn.decomposition import PCA
landmarks = ... # read landmarks for all training images
pca = PCA()
pca.fit(landmarks)
The role of this neural network then is to predict scores value for a given input image. I don’t have much to add about this step. Except that though the paper mentions normalizing rotation in PCA calculation by keeping the center point between eyes horizontally centered, I found that normalizing prevents the model from fitting around the eyes.
Debug training process
This exercise taught me a few things about debugging a neural network. The thing with a neural network is that there is no exception thrown, it still runs smoothly, just high validation loss. For example, during training, I realized that landmark points around the eyes keep scattering even when validation loss has plateaued. Changing learning rate and hyper parameters does not help. So I reduced the training set to a single image to see if the model is able to fit. Turned out it was not, which meant something is wrong with my model code. After going back to the paper provided code, I tried to remove the rotation normalizing step, trained again. And it worked!. The point is, trying to test on simple data first can help.
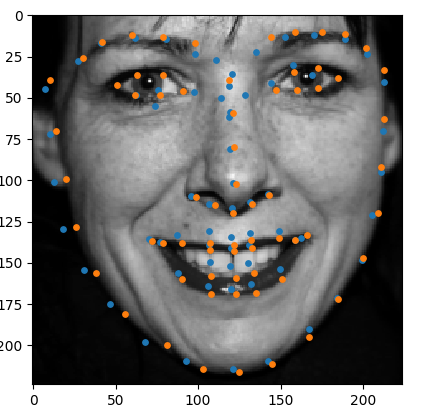
| Before | After |
|---|---|
 |
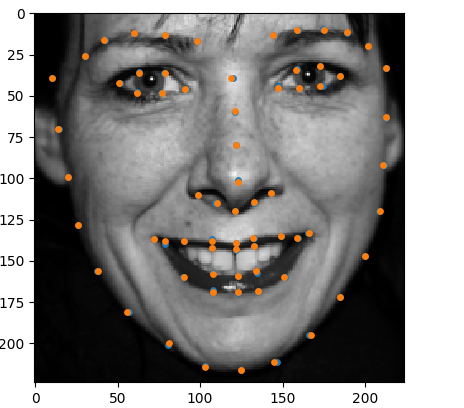 |
Orange markers are pre-defined landmarks and blue ones are predicted by the model. After PCA change, 2 set of landmarks overlap correctly.
Things todo after this
Training data set is only more than 6000 images. Augmentating training data (random scale & rotation) can help make the model more adaptive to new image. And since this paper is about how fast it can predict face landmarks, it is necessary to test the claim on mobile device, which may involve converting the Pytorch model to Caffe2 or some thing. Will try it on when time allows.
Update: There is an implementation of Shapenet in Tensorflow as mentioned in another post.